Early last year, I finished a paper for the Master of Science in Information Security Engineering program at SANS Technology Institute. The paper was published at SANS.org and SANS.edu a year ago but I am just now writing about the project here since life was pretty busy at the time.
I spent several years thinking through this problem and trying different technologies to make it work. I spent a few months finalizing it then writing it up for the academic paper (during which time I also had to, um... think about... this totally hypothetical disaster for several months...).
Rather than rewriting my paper as a blog post, I will include some of the most important parts of the paper, add some additional commentary, then refer you to the paper as needed. If you are actually interested in this solution, please read the paper since it has many more details.
Problem: Potential attack vector
As seen in real life on an HPC login node:
tcp 0 0 0.0.0.0:48279 0.0.0.0:* LISTEN 123965/mpiexec
tcp 0 0 0.0.0.0:6104 0.0.0.0:* LISTEN 107345/Xorg
tcp 0 0 0.0.0.0:39000 0.0.0.0:* LISTEN 213053/node
tcp 0 0 0.0.0.0:39001 0.0.0.0:* LISTEN 212528/mongod
tcp 0 0 0.0.0.0:39002 0.0.0.0:* LISTEN 212606/python
tcp 0 0 0.0.0.0:39003 0.0.0.0:* LISTEN 212788/python
tcp 0 0 0.0.0.0:39004 0.0.0.0:* LISTEN 212879/python
tcp 0 0 0.0.0.0:36846 0.0.0.0:* LISTEN 60839/java
tcp 0 0 127.0.0.1:63342 0.0.0.0:* LISTEN 60839/java
tcp 0 0 0.0.0.0:45621 0.0.0.0:* LISTEN 60839/java
tcp 0 0 0.0.0.0:43727 0.0.0.0:* LISTEN 6473/mpiexec
tcp 0 0 0.0.0.0:56733 0.0.0.0:* LISTEN 219999/mpiexec
tcp 0 0 0.0.0.0:33374 0.0.0.0:* LISTEN 175150/mpiexec
tcp 0 0 0.0.0.0:37987 0.0.0.0:* LISTEN 199971/mpiexec
tcp 0 0 0.0.0.0:44228 0.0.0.0:* LISTEN 123965/mpiexec
tcp 0 0 0.0.0.0:52294 0.0.0.0:* LISTEN 264169/mpiexec
These processes were all owned by various HPC users and there were probably dozens of people logged into that system at that moment.
I'll be lazy and quote from the paper's abstract:
In High Performance Computing (HPC) environments, hundreds of users can be logged in and running batch jobs simultaneously on clusters of servers in a multi-user environment. Security controls may be in place for much of the overall HPC environment, but user network communication is rarely included in those controls. Some users run software that must listen on arbitrary network ports, exposing user software to attacks by others. This creates the possibility of account compromise by fellow users who have access to those same servers and networks. A solution was developed to transparently segregate users from each other both locally and over the network. The result is easy to install and administer.
Basically, HPC users can typically open any network ports they want. Those ports typically need to be available across the entire subnet so that multi-node jobs can communicate with that port. As a result, it is almost impossible to create a useful firewall configuration for on-subnet traffic.
This arrangement allows users to potentially attack each other's software through vulnerabilities, mis-configurations, etc. We all know how excited a typical user is to securely set up software that they will routinely patch forever.
User-on-user attacks may seem unlikely, but advanced attackers may use this method if other attack vectors are unavailable. For example, let's say that an attacker compromises a user's account but can't find a way to escalate privileges. The attacker could then seek out a different user of the system who has high value data (maybe export-controlled data that they are after). If the target user opens network sockets, the attacker could take advantage of it and pivot to that user's account. SSH private keys could also be harvested to hop to other targets on or off the network.
This could be prevented if users are unable to talk to each other's processes over the network (including localhost).
Solution Overview
The goals of the solution I created are to:
- Isolate users on localhost
- Isolate users across hosts
- Minimize performance impact
- Easy installation and configuration
The solution addresses network attacks on user software by creating per-user VXLAN networks and Linux VRFs.
This isolates users from each other in a way that is completely transparent to the users. No user can talk to any other user's software over IP networks, including on localhost. They can, however, continue to communicate with their own processes across the network, talk to sshd and slurmd on localhost and over the network, and talk to off-network systems (if allowed by administrators).
Here is an example of what a host's networking may look like. I'll explain it more further down the page.
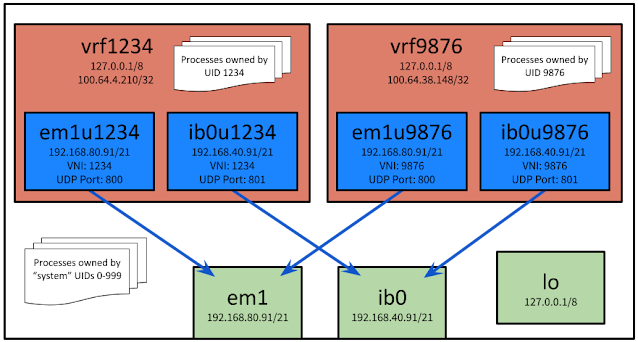 |
| Example system configuration with two physical interfaces (green), a loopback interface (green), four VXLAN interfaces (blue), and two VRFs (red). |
In order for this to work, all you need is a bash script and a trivial SPANK plugin (assuming you use Slurm) that I wrote. The bash script gets called by pam_exec.so and the SPANK plugin takes care of processes launched through Slurm. That's it. It works.
I call this setup "User Virtual Networks" (UVN) because I am not creative. If someone else has a better name, I am all for changing it.
Constraints that led to choosing VXLAN+VRF
This solution was developed with many constraints and assumptions that seem reasonable to me. If not for these constraints, the certain replies of "containers", "namespaces", "virtual machines", "SDN", or other technologies from DevOps and enterprise IT administrators would likely be warranted.
Some of these constraints are based on my knowledge of typical HPC environments, the desire to minimize the overall complexity of the solution, various limitations of existing technologies, and the impact of the solution on performance.
The most limiting constraints relate to making all changes transparent to the user. All changes must be transparent when the user communicates on localhost, across a locally-attached subnet (referred to as "on-subnet" going forward), and to a remote network (referred to as "off-subnet" going forward).
A user must be able to connect to the network ports they open for their own services but not to the network ports opened by other users. Additionally, the user must be able to access system services (e.g. sshd, Slurm, DNS if there is a local caching server, etc.) that are available on localhost through 127.0.0.1, ::1, and other local IP addresses.
See sections 2, 3.2.1, and Appendix A of the paper for more discussion of why various technologies were not chosen. Here is an incomplete list of options I considered and rejected for various reasons:
- GENEVE (see footnote 12 in section 3.1)
- MACsec (see A.1 in Appendix A)
- VLAN (see A.2 in Appendix A)
- Stacked VLANs / QinQ / IEEE 802.1ad (see A.2 in Appendix A)
- Network namespaces (see section 2.1, 3.2.1, and Appendix B)
- Subnet per user (see A.3 in Appendix A)
- Pretty much anything else listed at the time of the paper in ip link (some of it is too poorly documented for me to understand it)
VXLAN
VXLAN is very similar in concept to VLANs, though it has some big differences. VXLAN is a relatively simple protocol that encapsulates Ethernet packets in UDP packets and can be set up as a point-to-point tunnel or in a multicast group. It has a 24-bit VXLAN Network Identifier (VNI) as opposed to the 12-bit VLAN Identifier (VID), resulting in over 16 million usable network identifiers compared to VLAN's 4,094 identifiers.
VXLAN can use multicast to discover peers then transition to unicast after the discovery. This results in minimal effort to create a working configuration while benefiting from unicast's performance.
For this project, each user is assigned a unique VNI based on the user's UID on
Linux. This effectively creates a unique network for each user.
IP over InfiniBand (IPoIB) and other non-Ethernet IP networks are supported since VXLAN is UDP-based and can function on any IP network. VXLAN cannot be used to isolate native InfiniBand traffic; PKEYs are the only solution for doing so.
VRF
VRFs (Virtual Routing and Forwarding) allow for separate routing tables to exist within the same system and for various processes to have different routes based on their VRF membership. VRFs can be described as a method to present a process with a view of the network that is different from the views that other processes see. They only affect Layer 3 functionality; Layer 2 protocols such as LLDP are unaffected.
VRFs and network namespaces can achieve some of the same goals, but they are
distinctly different and have their own sets of advantages and disadvantages. The paper discusses the disadvantages of network namespaces (for this particular application) in section 3.2.1.
VRFs provide network isolation between processes in different VRFs. A process
in one VRF cannot talk to a listening port in a different VRF. The following output
shows an example of using ip vrf exec to place the netcat program (nc) into two
existing VRFs for various tests:
[root@host ~]# ip vrf exec vrf9876 nc -l 5555 &
[1] 16841
[root@host ~]# echo HELLO | ip vrf exec vrf1234 nc 127.0.0.1 5555
Ncat: Connection refused.
[root@host ~]# echo HELLO | nc 127.0.0.1 5555
Ncat: Connection refused.
[root@host ~]# echo HELLO | ip vrf exec vrf9876 nc 127.0.0.1 5555
HELLO
[1]+ Done
ip vrf exec vrf9876 nc -l 5555
[root@host ~]#
The example demonstrates that a process in vrf1234 cannot talk to a listening port opened by a process in vrf9876. Not even root-owned processes in the default VRF can connect to processes in those users' VRFs. If processes owned by UID 1234 are assigned to vrf1234 and processes from UID 9876 are assigned to vrf9876, users with UIDs 1234 and 9876 are isolated from each other and from any other users on the system. It should be noted that even stricter isolation can be easily achieved using network namespaces, but with significantly increased complexity in other areas.
Since one of my goals is to allow user processes to continue communicating with sshd, slurmd, and other "system" processes on the localhost, a sysctl tweak is required to allow this. The following example shows the effect of changing tcp_l3mdev_accept to "1". Similar controls exist for udp and raw.
[root@host ~]# sysctl -w net.ipv4.tcp_l3mdev_accept=0
net.ipv4.tcp_l3mdev_accept = 0
[root@host ~]# ip vrf exec vrf1234 nc 127.0.0.1 22 </dev/null | head -1
Ncat: Connection refused.
[root@host ~]# sysctl -w net.ipv4.tcp_l3mdev_accept=1
net.ipv4.tcp_l3mdev_accept = 1
[root@host ~]# ip vrf exec vrf1234 nc 127.0.0.1 22 </dev/null | head -1
SSH-2.0-OpenSSH_8.0
[root@host ~]#
At first, a process in vrf1234 cannot talk to 127.0.0.1:22 since its process (sshd) is in a different VRF, the default VRF. After setting net.ipv4.tcp_l3mdev_accept=1, the process in vrf1234 is able to talk to 127.0.0.1:22. This occurs because of special functionality that allows processes in the default VRF to listen on all VRFs.
Implementation
Rather than let this blog post grow to the same length as the 30+ page paper I wrote, I'll explain the basic idea of how this works then let you read the paper if you want more details.
A bash script, create_uvn, was written to assemble a per-user (i.e. per-UID) networking configuration when a user logs into a system over ssh or launches a job through Slurm. The script ensures that various sysctl and iptables settings are in place, reorders the RPDB (Routing Policy Database) to the correct ordering for VRFs, creates a VRF per user, creates a VXLAN interface per user per "real" interface, and places a user's initial process in their VRF. It also handles locking to prevent concurrent execution attempts.
The script creates one VRF for the user. 127.0.0.1 and ::1 addresses (see footnote 21 in the paper for IPv6-not-working-with-older-kernels disclaimer) are added to the VRF so that those addresses continue to be accessible to the user; the loopback device "lo" only exists in the default VRF and would thus be inaccessible to the user due to reply packets not having a proper return path.
create_uvn then iterates through the available interfaces on the system, looking for IP addresses that are part of administrator-defined subnets of interest. An administrator would typically list all subnets of which nodes might be a member, whether on Ethernet, InfiniBand, or other networks. A VXLAN interface is created for the user on each discovered interface. This results in a per-user VXLAN interface for each "real" interface on the system.
For example, if em1 and ib0 both exist on a system and have IP addresses in the administrator-designated subnets, each user who logs in would have two VXLAN interfaces created for them that are bound to the "real" interfaces. The interfaces are named with the user's UID as part of the interface name (e.g. "em1u1234" for UID 1234 on interface em1).
I'm including the same diagram twice so it's easier to refer to here:
|
| REPEAT. Example system configuration with two physical interfaces (green), a loopback interface (green), four VXLAN interfaces (blue), and two VRFs (red). |
In this example, em1u1234 and em1u9876 are both virtual interfaces created as VXLAN overlay networks using the em1 physical interface. Processes for user with UID 1234 are created inside vrf1234. em1u1234 and ib0u1234 are both members of vrf1234 and only vrf1234. Only processes attached to vrf1234 can use those interfaces. Processes in vrf1234 cannot access network sockets in vrf9876 or any other VRF except for the default VRF.
Processes such as sshd would run in the default VRF (the white area in the diagram). Due to the net.ipv4.tcp_l3mdev_accept=1 setting, processes in vrf1234 and other VRFs can talk to sshd on any address that it is listening on, including 127.0.0.1. This is true even though 127.0.0.1 exists on three interfaces in the diagram.
Testing Environment
Nodes were tested in the following groups:
- Group A: Two nodes, each with:
- dual Intel Xeon Gold 6230 2.10 GHz processors with 20 cores each, totaling 40 cores
- 768 GiB RAM
- dual 25 Gb/s QLogic FastLinQ QL41000 Ethernet card, each connected to a separate Ethernet switch
- dual Mellanox MT27800 100 Gb/s EDR InfiniBand cards, each connected to a separate InfiniBand switch
- Group B: Up to sixteen nodes, each with:
- dual Intel Xeon CPU E5-2680v4 2.40GHz processors with 14 cores each, totaling 28 cores
- 128 GiB RAM
- 10 Gb/s Intel 82599ES Ethernet card
- Mellanox MT27500 56 Gb/s FDR InfiniBand card
I wish I had access to a larger test cluster but I couldn't justify using more resources than I did for the already lengthy testing.
Functionality Testing
I successfully tested the following scenarios:
- User isolation works on localhost
- User isolation works between nodes
- Users can connect to resources off of the network where such connections are allowed
- Users can connect to a listening port owned by the same user on a different node
- Users can ping between identical VRFs on different nodes
- Users can use ssh to connect between nodes
- Users can use srun to launch batch job steps between nodes
- Users can use sbatch to launch batch jobs on the nodes
- Users can launch MPI programs across nodes
The tests were run in an automated fashion and were 100% successful. I didn't mention it in the paper, but file system traffic is intentionally unaffected by the isolation (i.e. it still works).
Performance Testing
Setup
I tested performance using:
- iperf3
- for 120 seconds
- with 10 seconds of warmup time (-O 10)
- with CPU pinning on the server and client
- Spot-checks revealed 15% decreased bandwidth if the wrong CPU cores were chosen (NIC was attached to the other CPU), so I made sure to avoid that
- with an increasing number of simultaneous instances, up to eight in total
- was only used for two-node tests
- IMB-P2P from Intel MPI Benchmarks 2019 update 6
- High Performance Linpack (HPL)
A pair of nodes from Group A and a pair from Group B were used for two-node
testing. All tests were performed across all available network cards, both Ethernet and InfiniBand. Tests over InfiniBand were conducted using IPoIB. For Intel MPI Benchmarks and HPL, an additional test was performed in each node group where MPI was allowed to use its default discovery method. In each case, MPI chose the fastest InfiniBand interface and used native InfiniBand rather than IPoIB.
For each piece of software listed in the section above, the tests were performed
inside and outside a UVN setup created by create_uvn. The VRF and VXLAN interfaces already existed during all tests, whether they were used in that particular test or not. The systems were not rebooted or otherwise altered to remove those additional interfaces in between tests.
The eight- and sixteen-node tests omitted the iperf3 bandwidth tests since those tests are only applicable between two nodes. The IMB-P2P and HPL benchmarks were run in a similar manner to the two-node benchmarks.
All performance tests also included verification with the above-mentioned functionality tests.
Results
Performance testing showed negligible performance impact in many areas and
greater impacts in others. A very large number of test types were run. Unfortunately, there were so many data points to examine that it's difficult to succinctly compare the performance of this solution. The Analysis section (section 6) in the paper contains a more comprehensive analysis of the performance impact. The raw data is available at https://github.com/ryanbcox/uvn.
Conclusion
The solution works for its intended purpose and is easy to administer. It integrates seamlessly with ssh and Slurm. No modifications to user code, configurations, or workflows were required. MPI works flawlessly.
Testing confirmed the functionality of create_uvn and the environment it creates; it works perfectly. Users were completely segregated from each other from a network perspective on both local and remote hosts, aside from native InfiniBand traffic and Unix sockets. System services continue to be available without modification.
The solution is easy to install. Only two files are necessary: the bash script and a simple Slurm SPANK plugin. pam_exec.so is used to call the script for ssh connections.
VRFs are superior to network namespaces for this use case. VXLAN worked perfectly in this project, though better encapsulation technologies may exist.
Performance tests were promising, though far from definitive. Many real workloads would experience a negligible impact at most, even across eight or sixteen nodes. However, a subset of MPI benchmarks showed severe performance degradation when run across sixteen nodes; it is unclear what triggers the degradation of those tests' communication patterns. The performance tests could be considered a stress test of the solution using various communication patterns, something that is hopefully not done by real code in production.
Multi-node HPL runs further demonstrated that some MPI programs are only negligibly impacted, though even that impact may be attributable to jitter. Further performance testing is needed using actual HPC applications rather than benchmark tools.
The combination of VRFs and VXLAN is effective and simple to deploy. It is a good addition to a defense-in-depth strategy, assuming that the performance characteristics are acceptable to the HPC site.
More Information
- My original Master's paper.
- Slides for a presentation. Select the "View" menu within the browser-based PowerPoint's menu (not the browser's "View" menu) then click "Notes" to see the copious speaker notes I was asked to include.
- Github repo
You can contact me at ryan_cox@byu.edu with questions about this project. If you end up deploying or testing this (even if it doesn't work for you), I would love to hear about it.
No comments:
Post a Comment
Please leave any comments, questions, or suggestions below. If you find a better approach than what I have documented in my posts, please list that as well. I also enjoy hearing when my posts are beneficial to others.